
【php爬蟲(chóng)】百萬(wàn)級(jí)別知乎用戶數(shù)據(jù)爬取與分析
本程序是抓取知乎的用戶數(shù)據(jù),要能訪問(wèn)用戶個(gè)人頁(yè)面,需要用戶登錄后的才能訪問(wèn)。當(dāng)我們?cè)跒g覽器的頁(yè)面中點(diǎn)擊一個(gè)用戶頭像鏈接進(jìn)入用戶個(gè)人中心頁(yè)面的時(shí)候,之所以能夠看到...
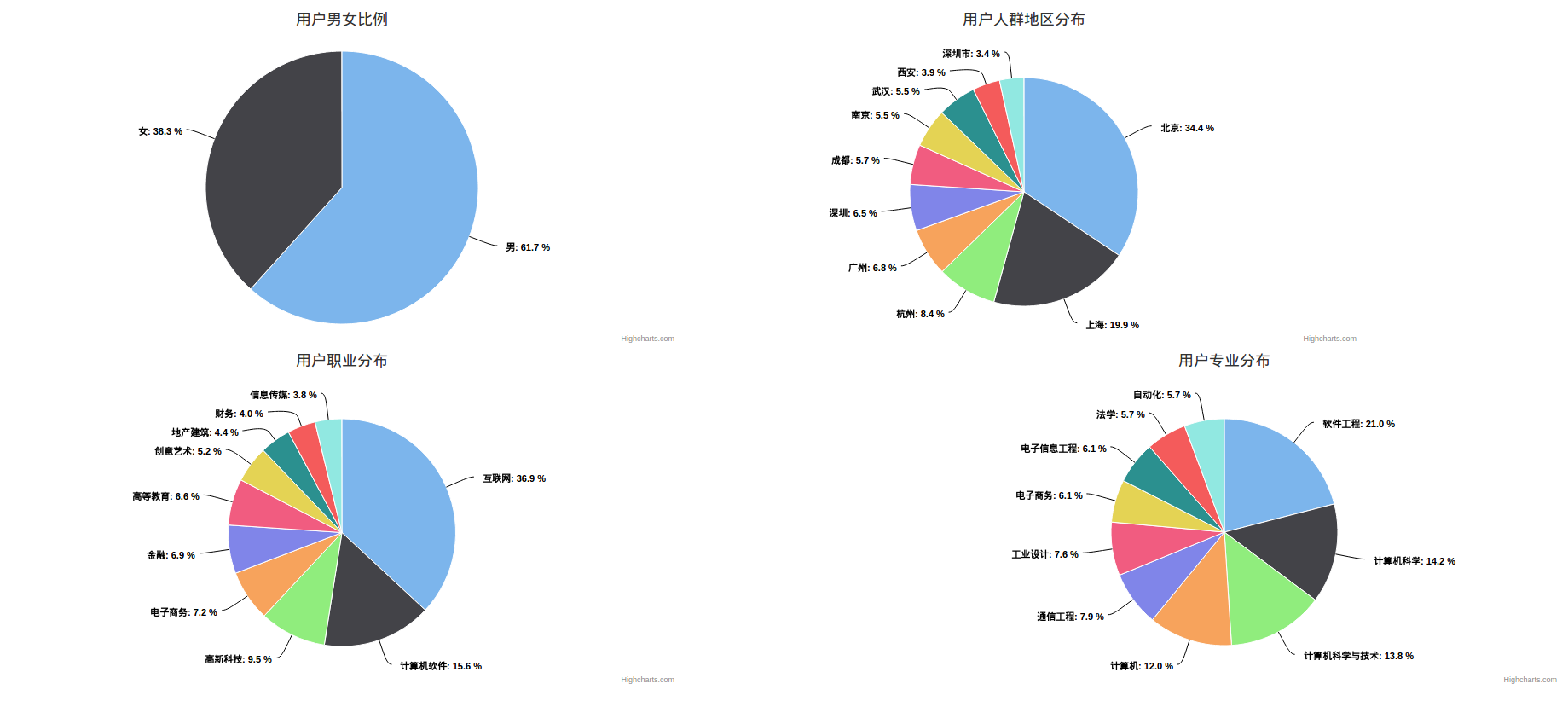
這次抓取了110萬(wàn)的用戶數(shù)據(jù),數(shù)據(jù)分析結(jié)果如下:
開(kāi)發(fā)前的準(zhǔn)備
安裝linux系統(tǒng)(Ubuntu14.04),在VMWare虛擬機(jī)下安裝一個(gè)Ubuntu;
安裝PHP5.6或以上版本;
安裝curl、pcntl擴(kuò)展。
使用PHP的curl擴(kuò)展抓取頁(yè)面數(shù)據(jù)
PHP的curl擴(kuò)展是PHP支持的允許你與各種服務(wù)器使用各種類型的協(xié)議進(jìn)行連接和通信的庫(kù)。
本程序是抓取知乎的用戶數(shù)據(jù),要能訪問(wèn)用戶個(gè)人頁(yè)面,需要用戶登錄后的才能訪問(wèn)。當(dāng)我們?cè)跒g覽器的頁(yè)面中點(diǎn)擊一個(gè)用戶頭像鏈接進(jìn)入用戶個(gè)人中心頁(yè)面的時(shí)候,之所以能夠看到用戶的信息,是因?yàn)樵邳c(diǎn)擊鏈接的時(shí)候,瀏覽器幫你將本地的cookie帶上一齊提交到新的頁(yè)面,所以你就能進(jìn)入到用戶的個(gè)人中心頁(yè)面。因此實(shí)現(xiàn)訪問(wèn)個(gè)人頁(yè)面之前需要先獲得用戶的cookie信息,然后在每次curl請(qǐng)求的時(shí)候帶上cookie信息。在獲取cookie信息方面,我是用了自己的cookie,在頁(yè)面中可以看到自己的cookie信息:
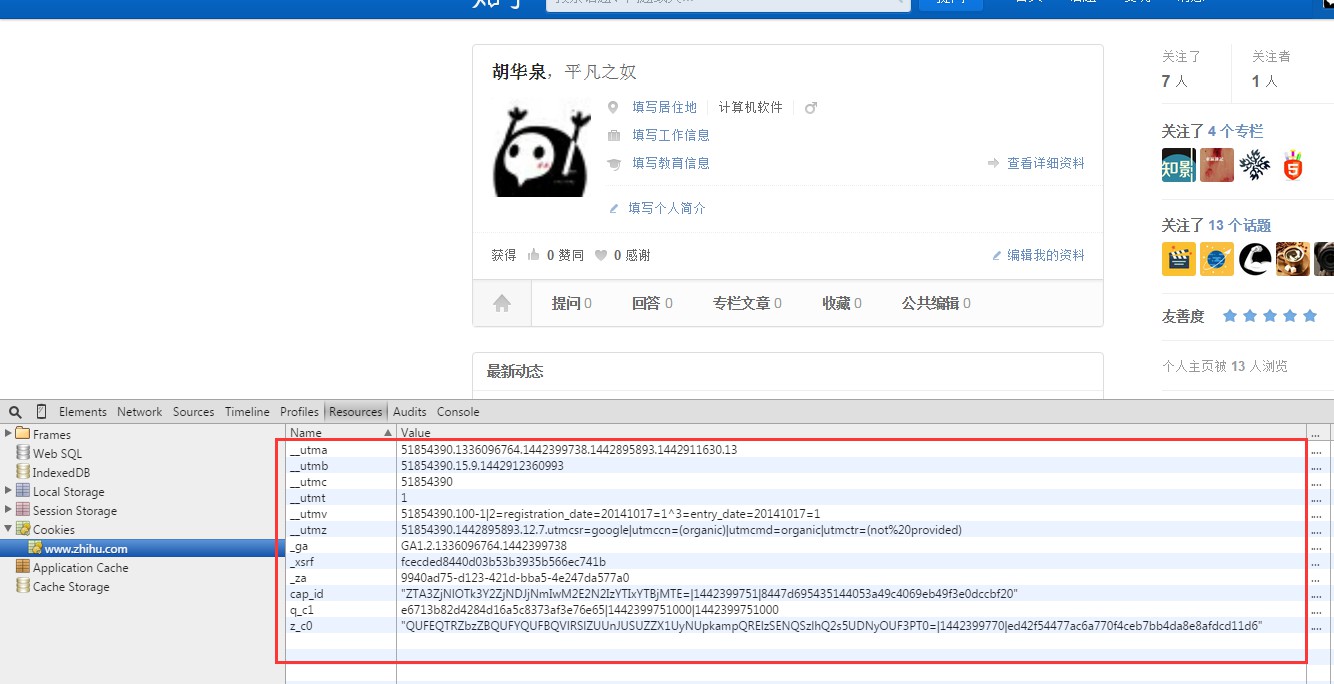
一個(gè)個(gè)地復(fù)制,以"__utma=?;__utmb=?;"這樣的形式組成一個(gè)cookie字符串。接下來(lái)就可以使用該cookie字符串來(lái)發(fā)送請(qǐng)求。
初始的示例:
$url = 'http://www.zhihu.com/people/mora-hu/about';
//此處mora-hu代表用戶ID $ch = curl_init($url);
//初始化會(huì)話 curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_COOKIE, $this->config_arr['user_cookie']);
//設(shè)置請(qǐng)求COOKIE curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
//將curl_exec()獲取的信息以文件流的形式返回,而不是直接輸出。 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$result = curl_exec($ch);
return $result; //抓取的結(jié)果
運(yùn)行上面的代碼可以獲得mora-hu用戶的個(gè)人中心頁(yè)面。利用該結(jié)果再使用正則表達(dá)式對(duì)頁(yè)面進(jìn)行處理,就能獲取到姓名,性別等所需要抓取的信息。
圖片防盜鏈
在對(duì)返回結(jié)果進(jìn)行正則處理后輸出個(gè)人信息的時(shí)候,發(fā)現(xiàn)在頁(yè)面中輸出用戶頭像時(shí)無(wú)法打開(kāi)。經(jīng)過(guò)查閱資料得知,是因?yàn)橹鯇?duì)圖片做了防盜鏈處理。解決方案就是請(qǐng)求圖片的時(shí)候在請(qǐng)求頭里偽造一個(gè)referer。
在使用正則表達(dá)式獲取到圖片的鏈接之后,再發(fā)一次請(qǐng)求,這時(shí)候帶上圖片請(qǐng)求的來(lái)源,說(shuō)明該請(qǐng)求來(lái)自知乎網(wǎng)站的轉(zhuǎn)發(fā)。具體例子如下:
function getImg($url, $u_id){
if (file_exists('./images/' . $u_id . ".jpg"))
{
return "images/$u_id" . '.jpg'; } if (empty($url))
{
return '';
}
$context_options = array(
'http' => array(
'header' => "Referer:http://www.zhihu.com"//帶上referer參數(shù) )
);
$context = stream_context_create($context_options);
$img = file_get_contents('http:' . $url, FALSE, $context);
file_put_contents('./images/' . $u_id . ".jpg", $img);
return "images/$u_id" . '.jpg';}
爬取更多用戶
抓取了自己的個(gè)人信息后,就需要再訪問(wèn)用戶的關(guān)注者和關(guān)注了的用戶列表獲取更多的用戶信息。然后一層一層地訪問(wèn)。可以看到,在個(gè)人中心頁(yè)面里,有兩個(gè)鏈接如下:
這里有兩個(gè)鏈接,一個(gè)是關(guān)注了,另一個(gè)是關(guān)注者,以“關(guān)注了”的鏈接為例。用正則匹配去匹配到相應(yīng)的鏈接,得到url之后用curl帶上cookie再發(fā)一次請(qǐng)求。抓取到用戶關(guān)注了的用于列表頁(yè)之后,可以得到下面的頁(yè)面:
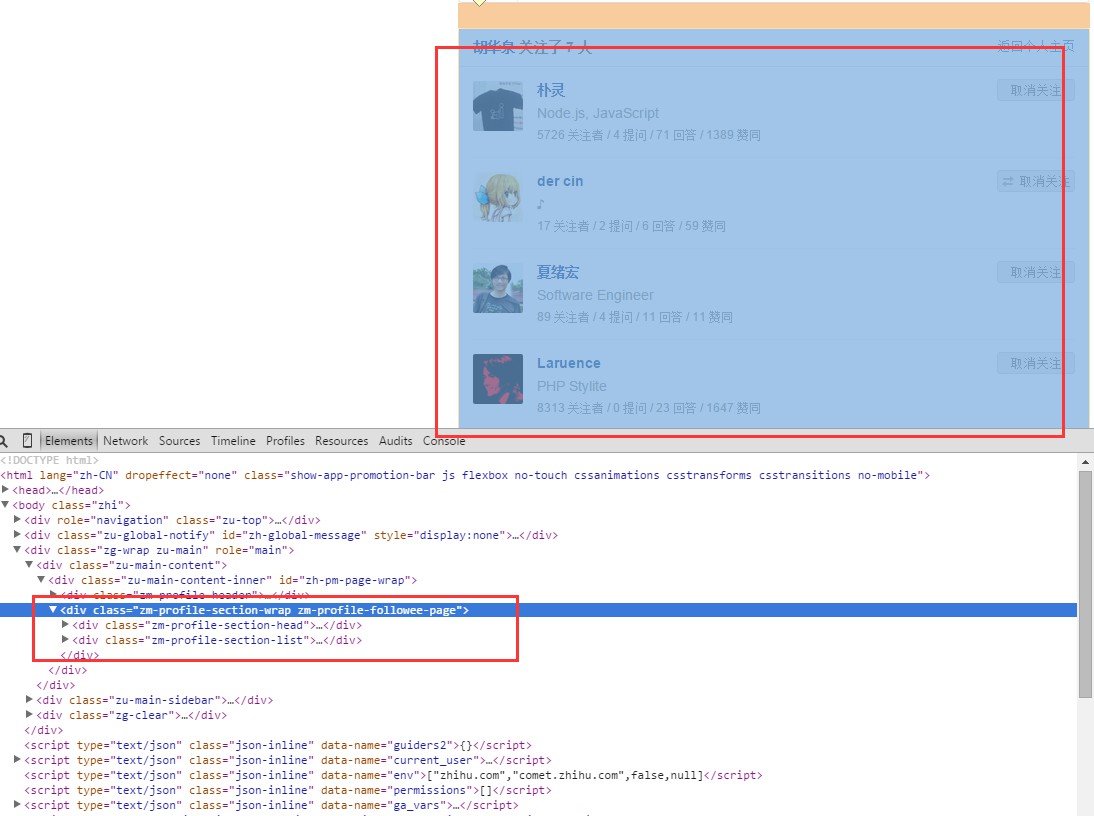
分析頁(yè)面的html結(jié)構(gòu),因?yàn)橹灰玫接脩舻男畔ⅲ灾恍枰蜃〉倪@一塊的div內(nèi)容,用戶名都在這里面。可以看到,用戶關(guān)注了的頁(yè)面的url是:

不同的用戶的這個(gè)url幾乎是一樣的,不同的地方就在于用戶名那里。用正則匹配拿到用戶名列表,一個(gè)一個(gè)地拼url,然后再逐個(gè)發(fā)請(qǐng)求(當(dāng)然,一個(gè)一個(gè)是比較慢的,下面有解決方案,這個(gè)稍后會(huì)說(shuō)到)。進(jìn)入到新用戶的頁(yè)面之后,再重復(fù)上面的步驟,就這樣不斷循環(huán),直到達(dá)到你所要的數(shù)據(jù)量。
- 我國(guó)于2018年前建成國(guó)家政府?dāng)?shù)據(jù)統(tǒng)一開(kāi)放門(mén)戶
- 百度推出網(wǎng)址檢測(cè)平臺(tái) “風(fēng)險(xiǎn)網(wǎng)站”誤判可申訴
- 網(wǎng)站盈利模式其實(shí)只有三種
- 站長(zhǎng)必看:四個(gè)決定網(wǎng)站生死的重要因素
- 談?wù)勎抑两?年的網(wǎng)站建站、“優(yōu)化”之路
- 利用監(jiān)控寶網(wǎng)站監(jiān)控服務(wù)功能快速知曉網(wǎng)站/服務(wù)器穩(wěn)定
- 百度競(jìng)價(jià)如何結(jié)合營(yíng)銷QQ數(shù)據(jù)庫(kù)做網(wǎng)絡(luò)營(yíng)銷
- SEO優(yōu)化方案:菜譜網(wǎng)站整站優(yōu)化思路